Biography
Rami Al-Rfou is a Member of Technical Staff at OpenAI, where he is a founding member of the robotics effort and leads work on embodied foundation models.
Previously, Rami was a Senior Staff Research Scientist at Waymo Research, where he led foundational motion modeling work for forecasting and planning. His team developed scalable transformer-based approaches for motion prediction, scaling laws, and efficient distillation methods for deployment.
Before Waymo, Rami was a Staff Research Scientist at Google Research. He led and contributed to multilingual and token-free language modeling work including mT5, ByT5, and prompt tuning, and helped deploy assisted writing systems such as SmartReply and SmartCompose across Google products.
Rami received his PhD in Computer Science from Stony Brook University under the supervision of Prof. Steven Skiena. His research has focused on large-scale representation learning across language, graphs, and embodied systems.
Experience
Member of Technical Staff - TLM
OpenAI
Responsibilities include:
- Founding member of OpenAI robotics; helped define strategy, scope, and technical direction
- Built and led a robotics ML team spanning model, data, and evaluation
- Led early embodied scaling studies, tokenization design, and offline evaluation methodology
- Partnered across hardware, software, operations, and leadership to deliver end-to-end milestones
Senior Staff Research Scientist
Waymo Research
Responsibilities include:
- Led foundational motion modeling research for forecasting and planning
- Developed scaling laws for open-loop and closed-loop motion metrics
- Designed efficient multimodal behavior models and distillation methods for deployment
- Managed and grew the foundational models research team
Staff Research Scientist
Google Research
Responsibilities include:
- Led multilingual LLM research including mT5 and ByT5
- Co-developed parameter-efficient prompt tuning methods
- Technical lead for multilingual SmartReply and SmartCompose systems
- Led deep retrieval and retrieval-augmented language modeling efforts
Research Intern
Microsoft Research
Research Intern
Google Research
Software Engineer Intern
Education
PhD in Natural Language Processing
Stony Brook University
BSc. in Computer Engineering
University of Jordan
Talks
Projects

Selected Publications
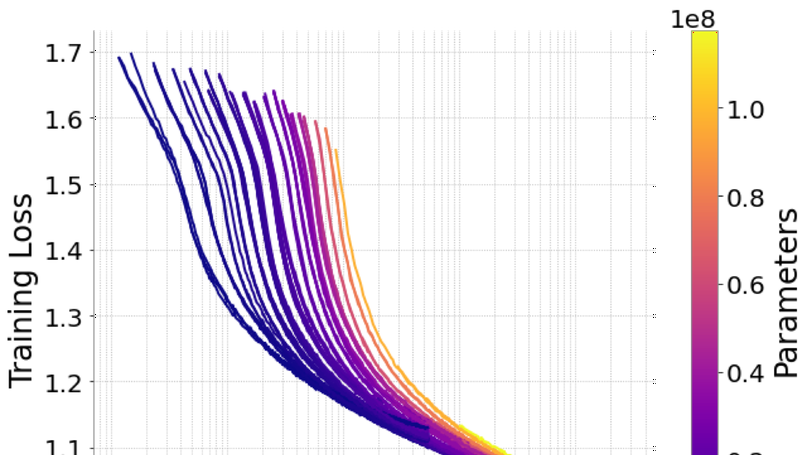
Scaling Laws of Motion Forecasting and Planning
Scaling behavior for motion forecasting and planning models in autonomous driving.
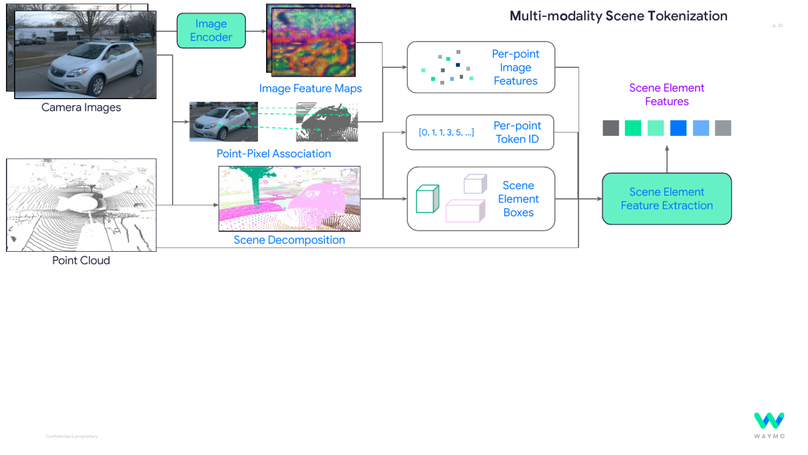
MoST: Multi-modality Scene Tokenization for Motion Prediction
Multi-modality scene tokenization for motion prediction.
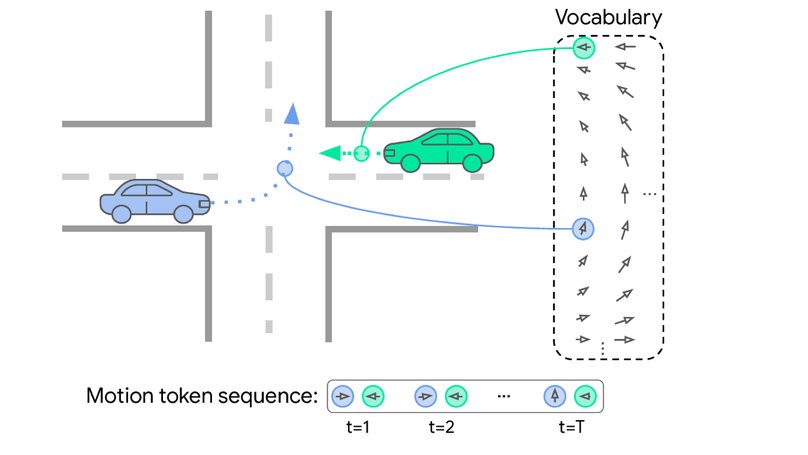
MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Multi-agent motion forecasting as language modeling.
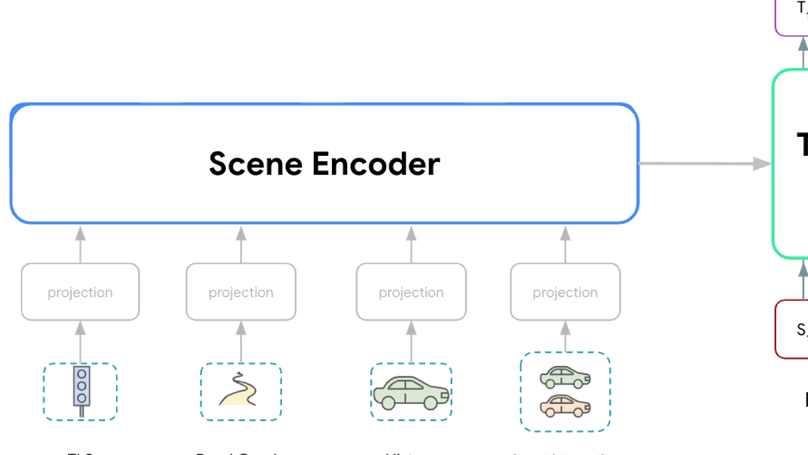
Wayformer: Motion Forecasting via Simple and Efficient Attention Networks
Efficient attention architecture for motion forecasting.
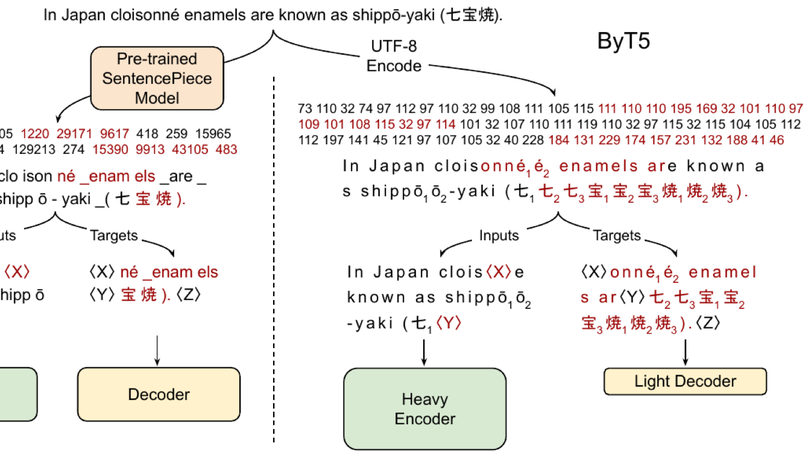
ByT5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
Token-free byte-to-byte language modeling at scale.
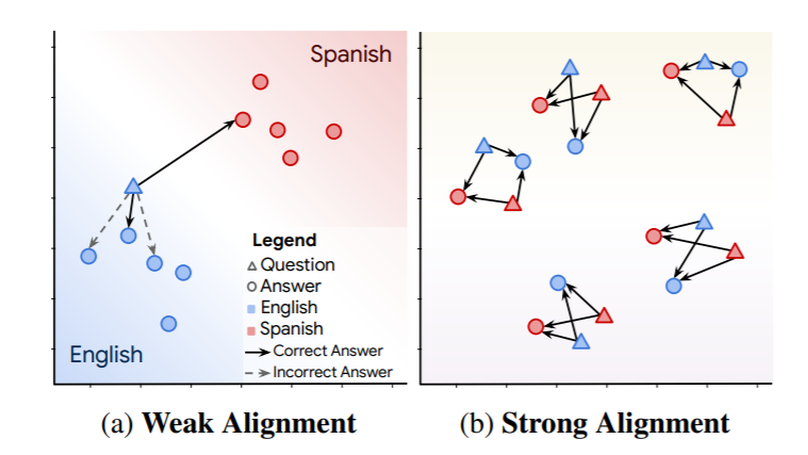
LAReQA: Language-agnostic answer retrieval from a multilingual pool
We present LAReQA, a challenging new benchmark for language-agnostic answer retrieval from a multilingual candidate pool. Unlike previous cross-lingual tasks, LAReQA tests for “strong” cross-lingual alignment, requiring semantically related cross-language pairs to be closer in representation space than unrelated same-language pairs. This level of alignment is important for the practical task of cross-lingual information retrieval. Building on multilingual BERT (mBERT), we study different strategies for achieving strong alignment. We find that augmenting training data via machine translation is effective, and improves significantly over using mBERT outof-the-box. Interestingly, model performance on zero-shot variants of our task that only target “weak” alignment is not predictive of performance on LAReQA. This finding underscores our claim that language-agnostic retrieval is a substantively new kind of crosslingual evaluation, and suggests that measuring both weak and strong alignment will be important for improving cross-lingual systems going forward. We release our dataset and evaluation code at https://github.com/google-research-datasets/lareqa
Recent Publications
Scaling Laws of Motion Forecasting and Planning
Scaling behavior for motion forecasting and planning models in autonomous driving.
MoST: Multi-modality Scene Tokenization for Motion Prediction
Multi-modality scene tokenization for motion prediction.
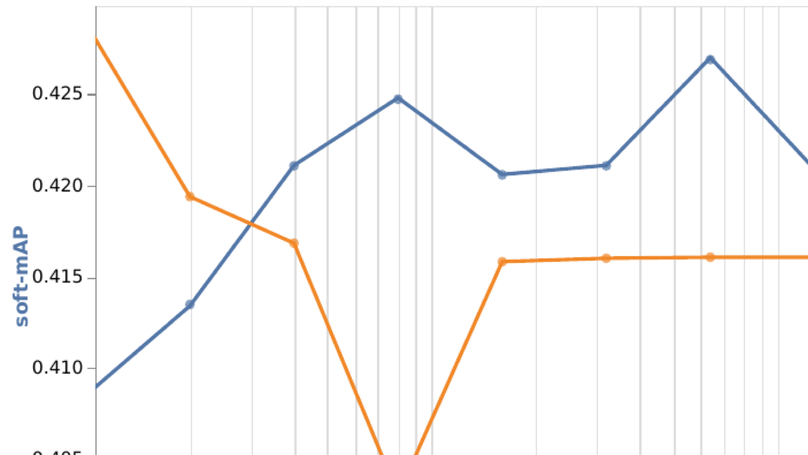
Scaling Motion Forecasting Models with Ensemble Distillation
Distillation methods for scaling motion forecasting models.
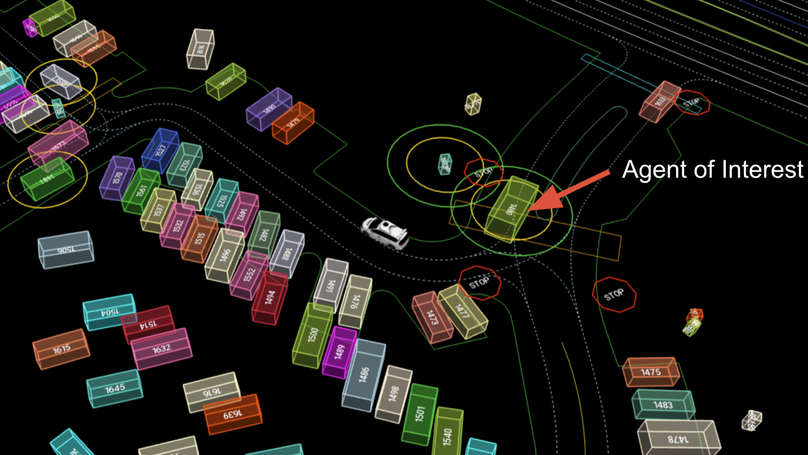
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
A raw sensor benchmark for motion forecasting.
MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Multi-agent motion forecasting as language modeling.
Wayformer: Motion Forecasting via Simple and Efficient Attention Networks
Efficient attention architecture for motion forecasting.
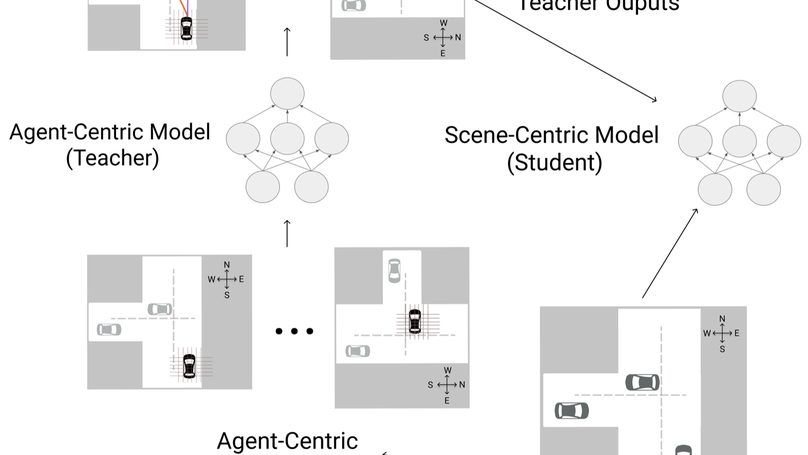
Narrowing the Coordinate-Frame Gap in Behavior Prediction Models
Distillation for efficient and accurate scene-centric motion forecasting.
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
Soft prompt transfer for better adaptation of frozen models.
ByT5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
Token-free byte-to-byte language modeling at scale.
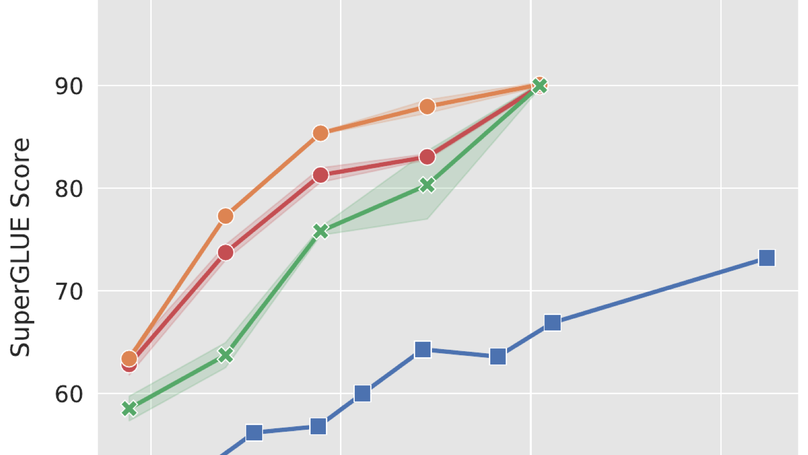
The Power of Scale for Parameter-Efficient Prompt Tuning
Prompt tuning improves substantially with model scale.

nmT5: Is Parallel Data Still Relevant for Pre-training Massively Multilingual Language Models?
Parallel data and pre-training dynamics for massively multilingual LMs.
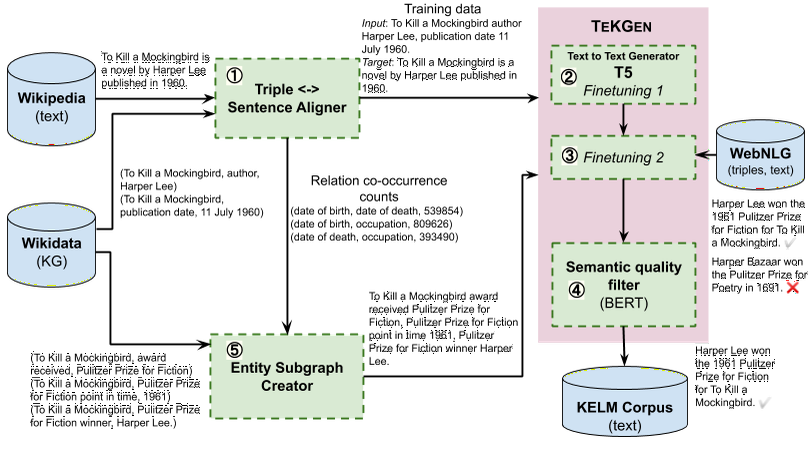
Large Scale Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
Prior work on Data-To-Text Generation, the task of converting knowledge graph (KG) triples into natural text, focused on domain-specific benchmark datasets. In this paper, however, we verbalize the entire English Wikidata KG, and discuss the unique challenges associated with a broad, open-domain, large-scale verbalization. We further show that verbalizing a comprehensive, encyclopedic KG like Wikidata can be used to integrate structured and natural language to overcome the incompleteness of both sources. In contrast to the many architectures that have been developed to integrate the structural differences between these two sources, our approach converts the KG into natural text, allowing it to be seamlessly integrated into existing language models. It carries the further advantages of improved factual accuracy and reduced toxicity in the resulting language model. We evaluate this approach by augmenting the retrieval corpus in a retrieval language model and showing significant improvements on the knowledge intensive tasks of open domain QA and the LAMA knowledge probe.
Patents
Parameter efficient prompt tuning for efficient models at scale
US Patent 12,524,711 (2026)Trajectory prediction using efficient attention neural networks
US Patent 12,497,079 (2025)Adapting foundation models for autonomous driving
US Patent App. 19/209,351 (2025)Scene tokenization for motion prediction
US Patent App. 18/950,830 (2025)Behavior prediction using scene-centric representations
US Patent App. 18/913,074 (2025)