Large Scale Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
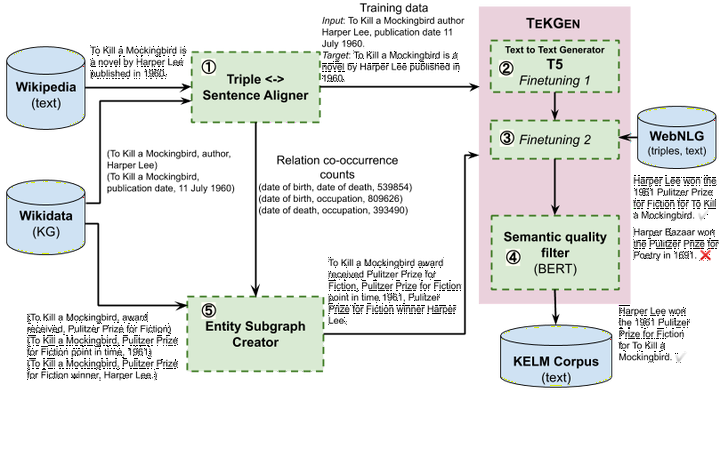 Image credit: Unsplash
Image credit: UnsplashAbstract
Prior work on Data-To-Text Generation, the task of converting knowledge graph (KG) triples into natural text, focused on domain-specific benchmark datasets. In this paper, however, we verbalize the entire English Wikidata KG, and discuss the unique challenges associated with a broad, open-domain, large-scale verbalization. We further show that verbalizing a comprehensive, encyclopedic KG like Wikidata can be used to integrate structured and natural language to overcome the incompleteness of both sources. In contrast to the many architectures that have been developed to integrate the structural differences between these two sources, our approach converts the KG into natural text, allowing it to be seamlessly integrated into existing language models. It carries the further advantages of improved factual accuracy and reduced toxicity in the resulting language model. We evaluate this approach by augmenting the retrieval corpus in a retrieval language model and showing significant improvements on the knowledge intensive tasks of open domain QA and the LAMA knowledge probe.
Rami Al-Rfou
Member of Technical Staff - TLM
My research interests include language modeling, embodied AI, motion forecasting, and multilingual modeling.