MoST: Multi-modality Scene Tokenization for Motion Prediction
Abstract
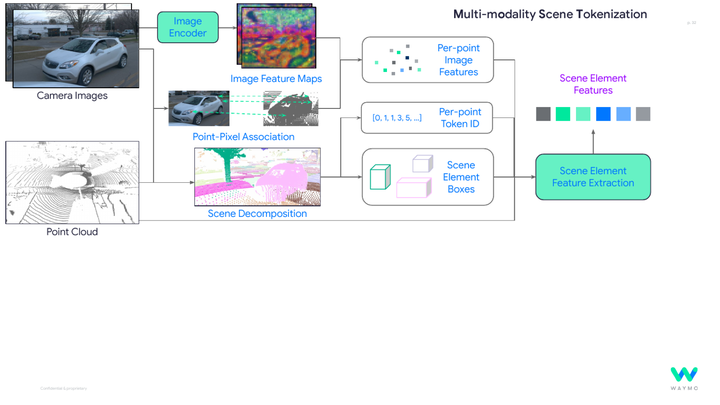
MoST introduces scene tokenization for multimodal motion prediction, improving representation quality and prediction performance.
Type
Publication
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rami Al-Rfou
Member of Technical Staff - TLM
My research interests include language modeling, embodied AI, motion forecasting, and multilingual modeling.