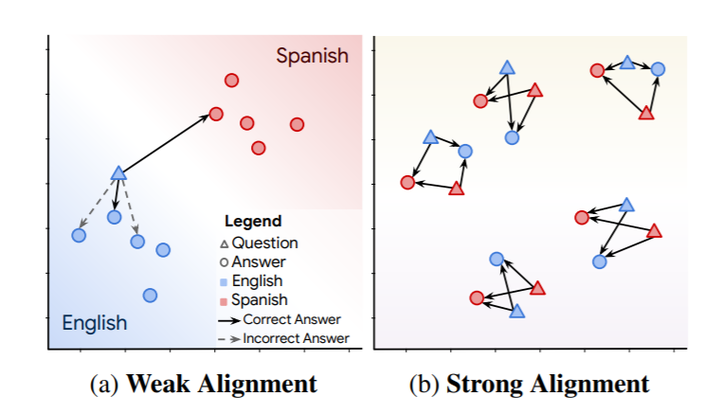
 A weakly aligned multilingual embedding space enables zero-shot transfer between languages, but incorrect answers in the same language are preferred over correct answers in a different language. A strongly aligned embedding space “factors out” language, so the most semantically relevant pairs are always the closest, regardless of language.
A weakly aligned multilingual embedding space enables zero-shot transfer between languages, but incorrect answers in the same language are preferred over correct answers in a different language. A strongly aligned embedding space “factors out” language, so the most semantically relevant pairs are always the closest, regardless of language.Abstract
We present LAReQA, a challenging new benchmark for language-agnostic answer retrieval from a multilingual candidate pool. Unlike previous cross-lingual tasks, LAReQA tests for “strong” cross-lingual alignment, requiring semantically related cross-language pairs to be closer in representation space than unrelated same-language pairs. This level of alignment is important for the practical task of cross-lingual information retrieval. Building on multilingual BERT (mBERT), we study different strategies for achieving strong alignment. We find that augmenting training data via machine translation is effective, and improves significantly over using mBERT outof-the-box. Interestingly, model performance on zero-shot variants of our task that only target “weak” alignment is not predictive of performance on LAReQA. This finding underscores our claim that language-agnostic retrieval is a substantively new kind of crosslingual evaluation, and suggests that measuring both weak and strong alignment will be important for improving cross-lingual systems going forward. We release our dataset and evaluation code at https://github.com/google-research-datasets/lareqa
Rami Al-Rfou
Member of Technical Staff - TLM
My research interests include language modeling, embodied AI, motion forecasting, and multilingual modeling.